This blog article is the final part of the three part series detailing the new Revisions feature in XJDeveloper 3.10. This article looks under the hood at how the device matching algorithm works.
If you missed the earlier posts in the series, you can go back and read an introduction to Revisions in part 1 or learn more about how the revision setup process works in part 2.
Why device matching?
Historically, the main issue with re-using your XJDeveloper project setup from one revision of a board to the next was device renumbering. XJDeveloper uses a device-centric model to setup your project and everything is keyed on reference designator, so if, for example, U27 is suddenly not U27 anymore then your old project is not much use. The new Revisions feature aims to overcome this problem by automatically identifying any reference designator changes and updating your project accordingly. The algorithm identifies a one-to-one mapping between devices in the source project and devices in the revision project and then copies across any device categorisations. It simultaneously updates the XJRunner test list, connections, constant pins and many other aspects of the project so you don’t have to. The end result is a much quicker transition from one design revision to the next while developing tests for your board.
How does it work?
The device matching algorithm pulls in all available data about the old and new revisions of the circuit to produce 1-to-1 matches between the source project and the revision. Each match is given a percentage confidence score which is then displayed in the Revision Checklist, 100% indicating a perfect match. Matches which the algorithm is very confident about are accepted automatically (but can be undone), others are presented as suggestions which you can either accept or reject.
The confidence score assigned to a match is made up of 4 separate factors:
- Reference designator match
- Bill of Materials (BOM) data match
- Pin count match
- Net topology match
The relative weightings of the different factors vary depending on the type of device being matched. You can mouse over any score in the Revision Checklist to display a tooltip with a detailed breakdown of all the contributions. I will go into more detail about each of the contributions below.
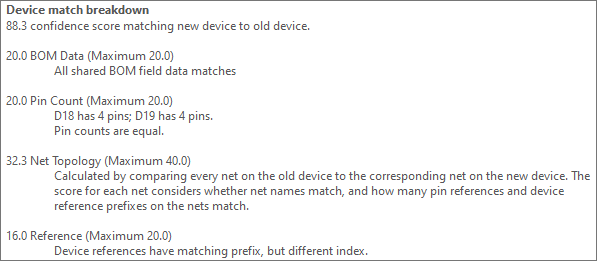
An example of the confidence score tooltip showing how the score is split up into the 4 separate contributions. These tooltips are very useful for determining whether a match is correct or not.
Reference Designator match
A very simple comparison, the score for this section is generated by comparing the reference designators of the two devices. If the two devices share the same prefix then they get the majority of this contribution. This creates a strong preference for matching devices of the same type, so we do not, for example, match a 20-way connector to a 20-pin IC. For two-pin devices like resistors and capacitors only devices with the same prefix are compared so this contribution is not used.
There is also a small contribution from devices having an exact number match but this is kept limited so as not to generate false positives when devices have been renumbered.
BOM data match
A score for this section is generated by comparing the data in the source project BOM and the revised BOM. Results can be improved by keeping the BOM format the same as much as possible between revisions. For each field in the BOM that is populated for both devices, they are scored for how closely the data matches. Numerical value, in the case of resistors and capacitors, is weighted higher than text fields.
Pin count match
Another very simple comparison, a maximum score for this section is given for an exact pin count match. A partial score is given for pin counts within 20%. For one and two-pin devices identical pin counts are required before any matches are considered so this contribution is not used.
Net topology match
The net topology contribution is the most complex part of the match algorithm and often provides the largest contribution to the final score. This score gives an indication of how similar a role in the circuit the two devices share. Whether they are on nets with the same name, and whether or not they can ‘see’ the same devices.
The score is generated by comparing the nets on like pins (same pin number) between two devices. Firstly, by comparing net names and then by comparing the other pin connections. A score is generated for each pin pair and then these scores are averaged to give the final contribution. This section in particular leads to remarkably accurate matches, typically 100% correct auto-matches and >90% correct suggestions across our test cases. Obviously on a medium-sized board with several hundred components, 90% means there will be false positives, so it is still important to check the suggestions the Revision Checklist provides, especially those with lower scores.
This concludes our 3-part series on the Revisions feature in XJDeveloper 3.10. We hope you find it helpful in your board setups. As always you can find out more by visiting the XJDeveloper help and selecting the “Revisions” chapter.
Leave A Comment